WorkFlowy / Dynalistの内容をScrapboxに貼り付けたとき、次のようなことが問題になります。
この2つの問題に対応できるツールは6つあります。それぞれの解説と機能比較はこちらをご覧ください。
本記事では、6つのツールのうちの1つであるscrapbox-converterというツールの使い方を解説します。
〈目次〉
scrapbox-converterの使い方
機能
- インポートによって作成されるScrapboxの各ページのタイトルは、手動で指定する必要があります。
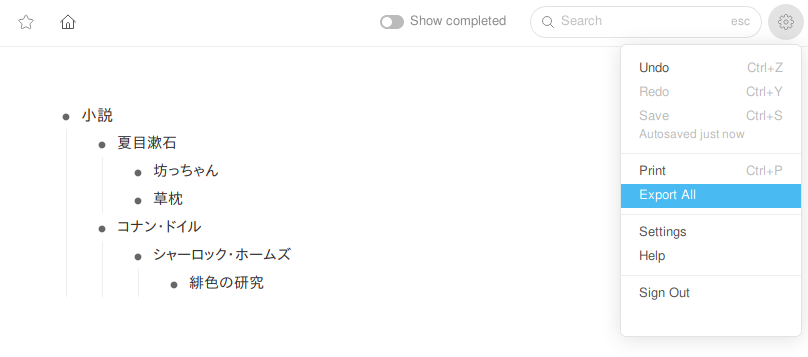
- インポート元がWorkFlowyの場合は、最上位の階層は箇条書きにならず、2階層め以下が箇条書きになります(こちらの画像の例では「小説」が最上位の階層)。
- 元のWorkFlowyと完全に同じにするためには、インポート後に手動で修正が必要です(後述)。
- インポート元がDynalistの場合は、見出し(H1〜H3)や、Markdownで指定した書式・ハイパーリンクなども正しく変換されます。
- Dynalistにおける「ドキュメント」のタイトルは引き継がれません。
- Dynalistの内容が画像を含む場合は、エラーが出るかもしれません。
必要なもの
Scrapboxにインポートする手順
WorkFlowyからインポートする場合は下記をご覧ください。Dynalistからインポートする場合はこちらをご覧ください。
WorkFlowyからのインポート
WorkFlowyにて、Scrapboxにインポートしたい部分を開き、画面右上の歯車アイコンもしくは一行目の右端にある「…」の形のアイコンをクリックし、“Export All”もしくは“Export”をクリック。
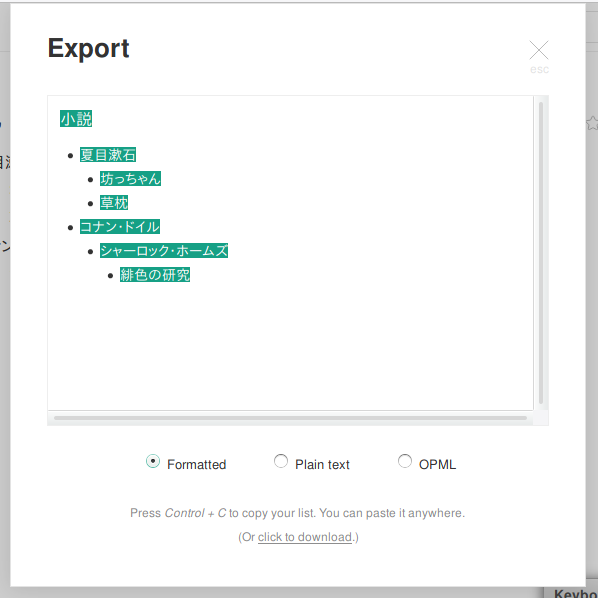
“Export”というタイトルのウィンドウが開きます。下の方にある選択欄で“Formatted”を選択し、一番下の“click to download”をクリック。
“workflowy-export.html”という名前のhtmlファイルがダウンロードされます。このhtmlファイルのファイル名(拡張子を除いた部分)が、Scrapboxへのインポート後にページのタイトルとなります。ファイル名を変える必要があれば変えます。ただし、
- インポート先のScrapboxに既に存在しているページのタイトルと重複しない名前をつける。
という条件を満たすようにファイル名を付けます。もし重複していると、Scrapboxに既に存在しているほうのページの内容が上書きされてしまうためです。
ここでは、例としてファイル名を“インポート1.html”としてみます。
次に、“インポート1.html”をテキストエディタで開きます。ファイル内の5行目あたりに<style>という文字があり、
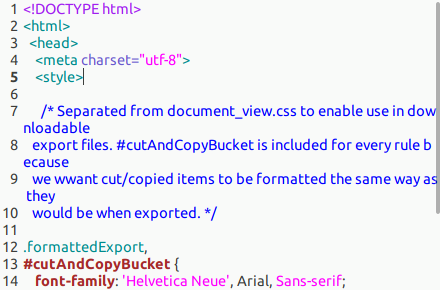
70行目あたりに</style>という文字があるはずです。この<style>と</style>で囲まれた部分(行数にして70行弱)を、テキストエディタで全て削除します。

削除しおわると、6行目付近まではこのようになっているはずです。

削除し終わったら“インポート1.html”を上書き保存。
次に、“インポート1.html”が置いてあるフォルダにて、端末(コマンドプロンプト, Terminal)で次のように実行します(末尾のjsonファイルのファイル名は自由に決めることができます。jsonファイルの名前を変えても、インポート後のページタイトルには影響しません)。
scrapbox-converter インポート1.html > インポート1.json
“インポート1.html”が保存されているのと同じフォルダに“インポート1.json”というファイルができます。
次に、インポート先となるScrapboxのプロジェクトの“Settings”の中の“Page Data”のタブを開きます。
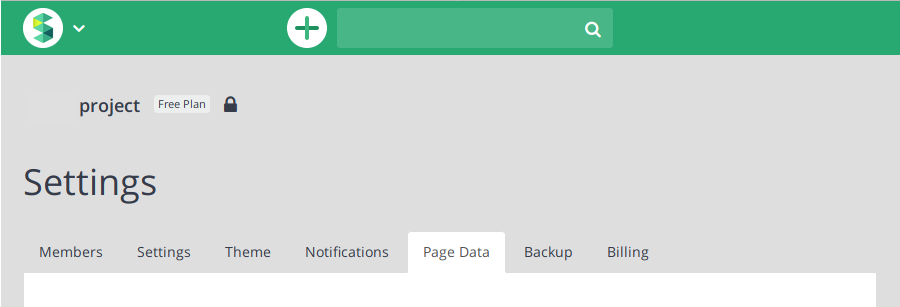
“Import Pages”のところで「参照」ボタンを押すとファイル選択のウィンドウが開くので、上述の手順で作られた“インポート1.json”を選択。Scrapboxの画面が下記のように変わったら、“Import Pages”をクリック。
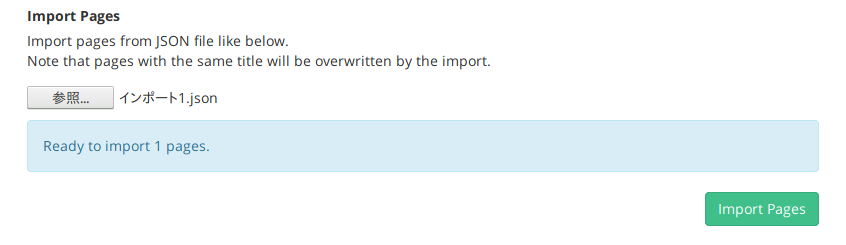
Scrapboxのトップページに自動で遷移します。「インポート1」というタイトルのページが作成されています。
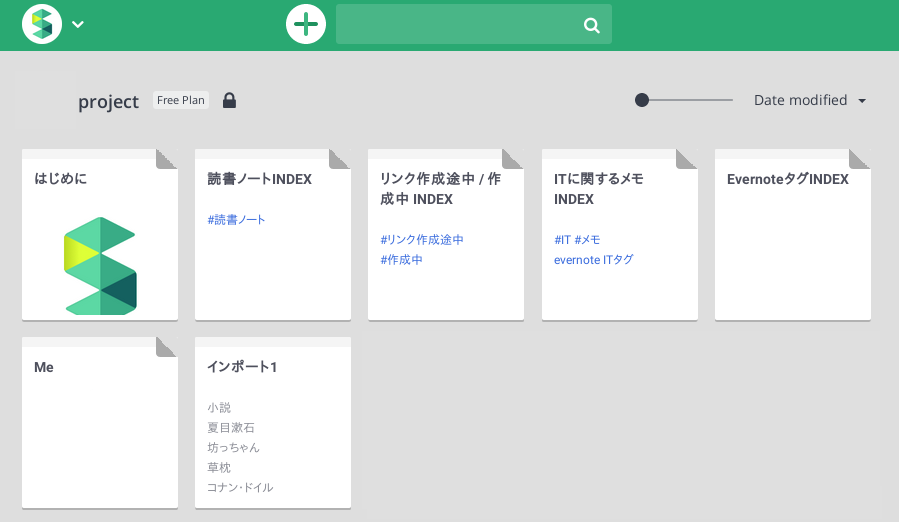
インポート後の修正(任意)
インポートされたページを開くと、WorkFlowyでの階層構造が再現されています。
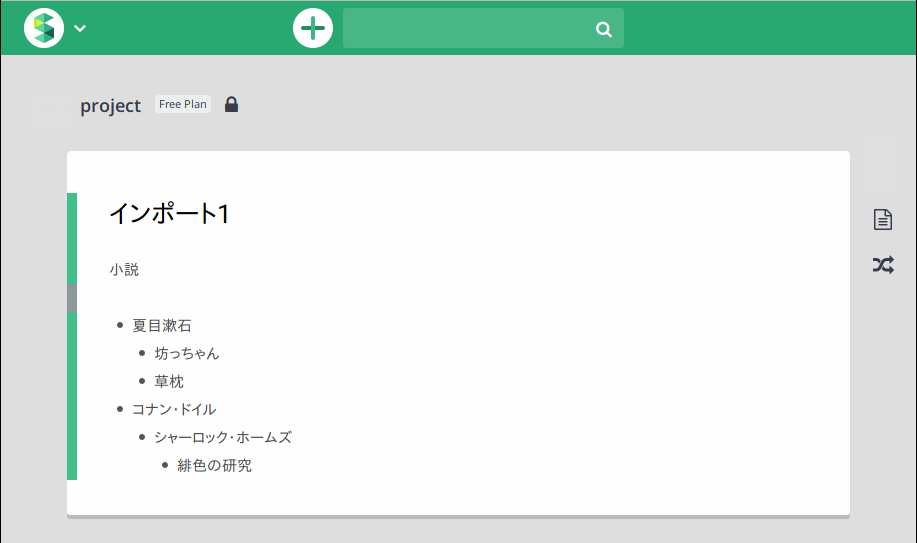
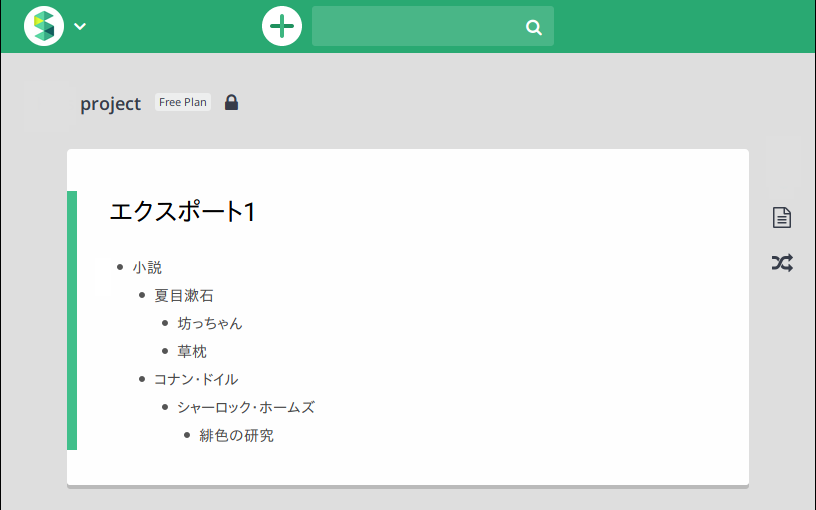
ただし先述のように、元のWorkFlowyで最上位の階層にあった内容(「小説」)はScrapboxで箇条書きになっていませんので、必要があれば箇条書き化し*3、2階層目以下をさらに1階層下げれば*4、元のWorkFlowyと同じ階層構造になります。また、デフォルトでは元のWorkFlowyでの1行目と2行目の間に空行が1行入るようですので、これも消したほうが万全でしょう。
それらの修正を加えるとこのようになります。
Dynalistからのインポート(htmlファイルの場合)
Dynalistにて、Scrapboxにインポートしたい部分を開きます。一行目にマウスカーソルを合わせると、行頭に「≡」の形のアイコンが現れるので、それをクリック。小さなウィンドウが表示されるので、その中の“Export”をクリック。
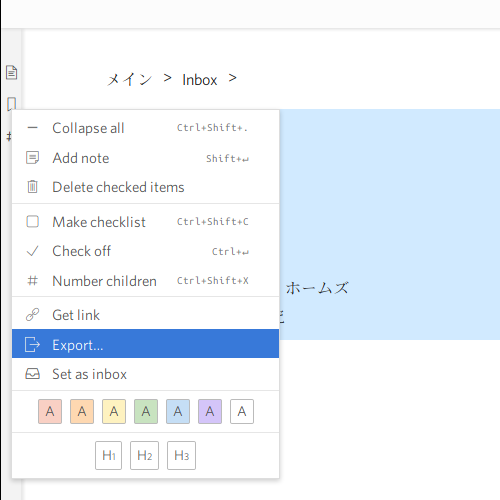
“Export”というタイトルのウィンドウが開きます。上の方にある3つのタブのうちの“Formatted”を選択し、一番下にある“Download as file”をクリック。
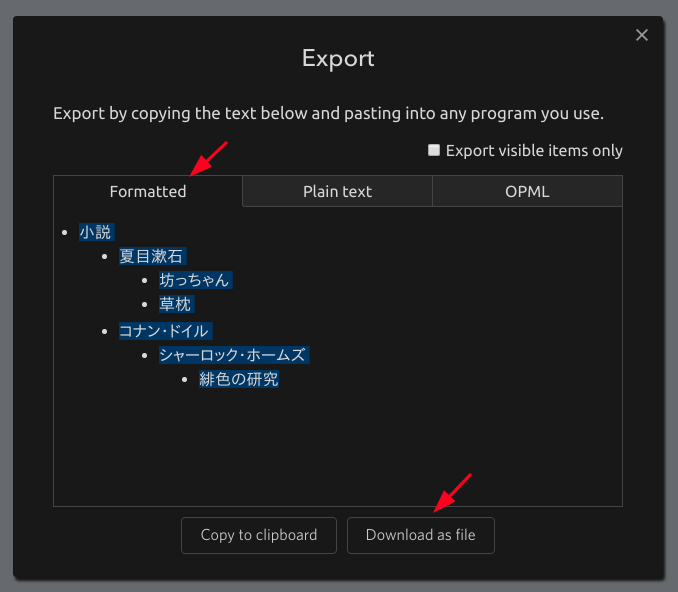
“dynalist-yyyy-mm-dd.html”という名前のhtmlファイルがダウンロードされます。このhtmlファイルのファイル名(拡張子を除いた部分)が、Scrapboxへのインポート後にページのタイトルとなります。ファイル名を変える必要があれば変えます。ただし、
- インポート先のScrapboxに既に存在しているページのタイトルと重複しない名前をつける。
という条件を満たすようにファイル名を付けます。もし重複していると、Scrapboxに既に存在しているほうのページの内容が上書きされてしまうためです。
ここでは、例としてファイル名を“インポート2.html”としてみます。
次に、“インポート2.html”が置いてあるフォルダにて、端末(コマンドプロンプト, Terminal)で次のように実行します(末尾のjsonファイルのファイル名は自由に決めることができます。jsonファイルの名前を変えても、インポート後のページタイトルには影響しません)。
scrapbox-converter インポート2.html > インポート2.json
“インポート2.html”が保存されているのと同じフォルダに“インポート2.json”というファイルができます。
次に、インポート先となるScrapboxのプロジェクトの“Settings”の中の“Page Data”のタブを開きます。
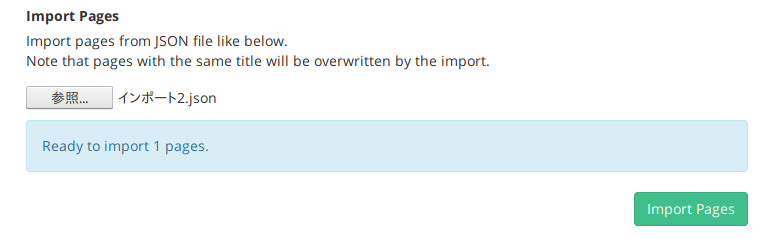
“Import Pages”のところで「参照」ボタンを押すとファイル選択のウィンドウが開くので、上述の手順で作られた“インポート2.json”を選択。Scrapboxの画面が下記のように変わったら、“Import Pages”をクリック。
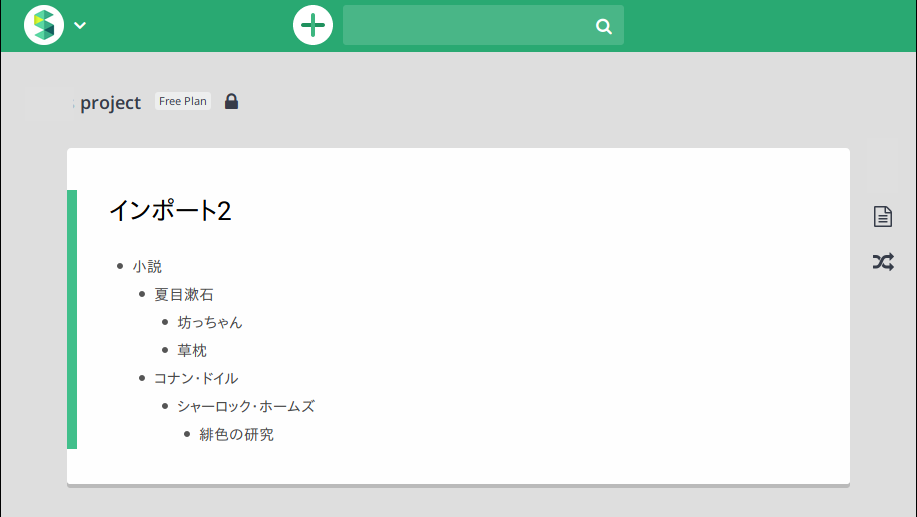
Scrapboxのトップページに自動で遷移します。「インポート2」というタイトルのページが作成されています。*5
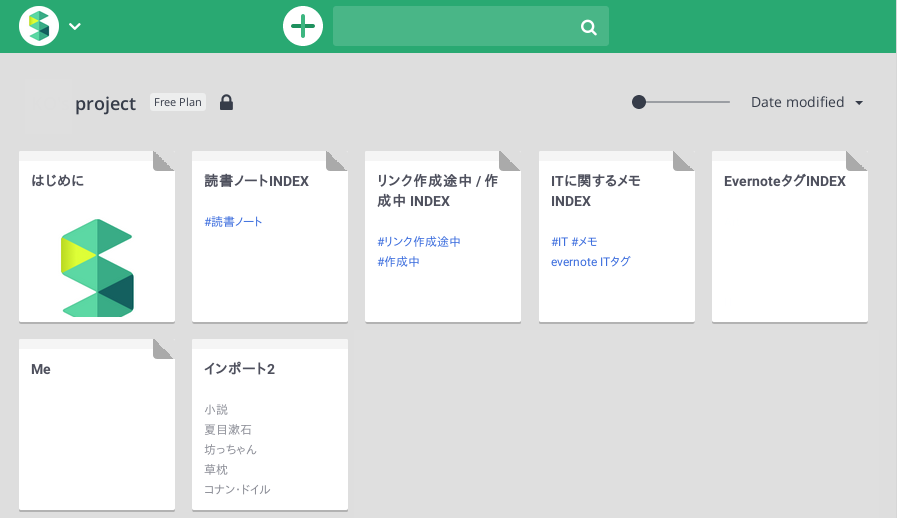
Dynalistでの階層構造が再現されています。
![Scrapbox情報整理術 [ 倉下忠憲 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/2525/9784863542525.jpg?_ex=128x128 "Scrapbox情報整理術 [ 倉下忠憲 ]")
- 価格: 2343 円
- 楽天で詳細を見る
![アウトライナー実践入門 「書く・考える・生活する」創造的アウトライン・プロ [ Tak. ]](https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/2858/9784774182858.jpg?_ex=128x128 "アウトライナー実践入門 「書く・考える・生活する」創造的アウトライン・プロ [ Tak. ]")
*1:筆者はnpmをManjaro Linuxにインストールして使用しています。Linuxであれば、それぞれのパッケージマネージャからインストールできると思います。
*2:Linuxなら sudo npm install -g scrapbox-converter とする必要があるかもしれません。
*3:箇条書きにするには、行頭に半角スペースを入れるか、行頭でTabキーを押す。
*4:2階層目以下を1階層下げるには、カーソルで範囲を選択をしたうえでTabキーを押す。
*5:インポートによって作成されたScrapboxのページ内に、もしも余分な記号類が見えていれば、こちらの要領でhtmlファイル内の<style>から</style>までの部分を削除してからインポートする必要があるかもしれません。